INDIGO TALK / 超级智能会从边缘涌现吗?- EP41

本期 Indigo Talk 邀请了十几年的老友田鸿飞,他曾是比特币的早期玩家,现在是边缘 AI 的创业者。我们聊到了一台跑图速度是 Mac Studio 7 倍的家用算力盒子 Olares;为什么苹果隐私做得最好却最赚钱;以及 DeepMind 那篇被忽视的论文 —— 超级智能可能从分布式协作中涌现;
录制这期节目的时候 ClawdBot(OpenClaw)还没有火爆,但对谈已经涉及到个人计算的本质:数据应该在哪里处理?隐私与便利真的是一对矛盾吗?当所有人都在追逐单一的超级智能时,分布式智能体的协作会不会是另一条通向 AGI 的路径?在 AI 时代,什么才是真正属于我们自己的?
也许当所有人仰望云端时,真正的革命可能正在你家桌上发生。
Apple Podcast & Spotify 播客 | 小宇宙播客
嘉宾
田鸿飞(Olares 联合创始人 / 远望资本合伙人)
Indigo(数字镜像博主 / 独立投资人)
时间戳
- 00:03:04 从微博到边缘智能 — 田鸿飞的个人背景
- 00:10:04 Olares 产品介绍 — 硬件规格与开源意义
- 00:15:33 远程桌面体验 — 应用生态与实际演示
- 00:23:25 三类用户画像 — 设计师、AI 工程师、小企业主
- 00:28:55 隐私与商业模式 — 苹果模式的深度分析
- 00:34:56 数字孪生 — “更像我”而非“更聪明”
- 00:41:12 分布式智能 — DeepMind 论文的启示
- 00:48:40 群蜂智能 — 股票市场作为成熟的 Agent 网络
- 00:54:20 特斯拉启示录 — “8倍效率”的商业逻辑
- 01:05:46 智能网络的未来 — Agent 支付与区块链
- 01:13:16 分布式理想的回归 — 从 Internet 到 Intelligent Web
超级智能会从边缘涌现吗?
这是一期关于边缘智能(Edge AI)的深度对谈。嘉宾田鸿飞,Olares 的联合创始人,也是远望资本的创始合伙人。鸿飞与主持人 Indigo 在微博创立期就相识,一个是微博的早期团队成员,另一个正在微博生态中创业,为企业提供营销数据服务。没有人会想到,十多年后,他们会坐在一起,讨论一个听起来像科幻小说的话题:如果每个人都拥有一台 AI 计算中心,超级智能会不会从这些分布式的"小智能"中涌现出来?
录制这期节目的时候 ClawdBot(OpenClaw)还没有火爆,但对谈已经涉及到个人计算的本质问题:数据应该在哪里处理?隐私与便利真的是一对矛盾吗?当所有人都在追逐单一的超级智能时,分布式智能体的协作会不会是另一条通向 AGI 的路径?而最终,在 AI 时代,什么才是真正属于我们自己的?
01. 从微博到边缘智能 —— 一个技术理想主义者的二十年
"我们认识十五六年了,一块穿越了好多时代。" Indigo 回忆道。
那是 2009 年前后,中国互联网正在经历移动互联网的黎明。微博刚刚诞生,正以惊人的速度改变着中国的社交媒体格局。田鸿飞当时的创业项目是在微博上帮企业做营销数据服务 —— 这在今天看来是个再普通不过的 SaaS 业务,但在那个年代,它代表着对新兴平台生态的敏锐嗅觉。
但如果你以为田鸿飞只是一个追逐风口的创业者,那就大错特错了。
一条不寻常的技术轨迹
2009 年来北京创业之前,田鸿飞在 Oracle 做安全工程师,专门负责加密和公钥基础设施(PKI)的包管理。这个看似枯燥的工作,却为他日后的人生埋下了重要的伏笔。
"当我读到比特币论文的时候,就有种很熟悉的感觉。" 田鸿飞回忆道。那是比特币诞生不久的年代,绝大多数人对这份白皮书背后的密码学原理一无所知,但对于一个长期处理公钥加密的安全工程师来说,中本聪的设计简直是一场密码学的优雅演出。
于是,在微博创业之后,田鸿飞做出了一个在当时看来颇为"离经叛道"的选择:去新疆做比特币服务公司。
"巨早,对,大佬。" Indigo 听到这里忍不住调侃。
这个选择透露出田鸿飞身上一个核心特质:他天生对去中心化的东西有种本能的亲近感。从 20 多年前在学校研究网格计算,到后来做微博第三方应用,再到比特币,他的技术轨迹一直围绕着一个核心主题:分布式、去中心化。
"天生比较反骨吧。" 田鸿飞自嘲道,但这份"反骨",恰恰是理解 Olares 这款产品的关键钥匙。
创新工场的交汇点
2015-16 年,田鸿飞转型做投资,投了很多机器人公司。而 Olares的 故事,要从创新工场说起。
Olares 的 CTO 叫彭鹏,是田鸿飞在创新工场的同事。创新工场最早做的项目之一是点心操作系统,后来团队孵化出了涂鸦移动。操作系统,这个词在彭鹏的技术基因里刻得很深。
"我们想做一个边缘智能的、面向 Agent 的操作系统,这是我们可以往回溯到十多年前的初心。" 田鸿飞说。
这个初心有一个具体的历史参照物:Android G1。
"年纪比较大的人都知道,Google 的第一个手机是 G1 HTC。我们现在做的 Olares One,就是一个类似于 Android G1 的、我们第一代 Agent OS 的软硬件结合产品。"
这个类比非常精准。Android G1 在 2008 年发布时,没有人能预见到 Android 日后会统治全球 85% 以上的智能手机市场。它是一个开端,一个可能性的证明,一个"操作系统可以是这样的"的宣言。
Olares 想做的,正是AI时代的"G1"。
02. Olares —— 重新定义家庭算力中心
在访谈中,主持人把 Olares One 拿到镜头前展示。这是一台和 Mac Studio 差不多大小的银色设备,外观简洁,接口极少 —— 只有一个 Thunderbolt 3、一个 HDMI、一个USB-A 和一个网线接口。
"接口非常少,是因为我们是一个云访问的设备。用户通过浏览器来访问它,不需要插上键盘和屏幕。" 田鸿飞解释道。
这意味着你可以把 Olares One 放在家里的任何角落 —— 书房的柜子里、路由器旁边、甚至藏在沙发后面——只要它连着网络和电源,你就可以在世界任何地方通过浏览器访问你自己的"私人云"。
硬件规格:5090 移动版与 96GB 显存
打开这台设备的规格表,你会发现一些让硬件爱好者眼前一亮的数字:
- GPU:NVIDIA 5090 移动版(实际性能约等于 5070 桌面版)
- 显存:96GB(这是最关键的数字)
- 售价:约 3000 美元
"我周围好多朋友买 5090 的卡在家里跑生图。" Indigo 说。这正是 Olares 瞄准的市场需求:越来越多的专业用户需要在本地运行大模型,而不是依赖云端服务。
96GB 显存是什么概念?如果你用过本地大模型,你会知道显存是最稀缺的资源。一个满血版的 DeepSeek R1(671B 参数)在4bit量化后大约需要 100-150GB 显存,而一般的消费级显卡只有 12-24GB 显存。96GB 的显存意味着你可以在本地运行绝大多数开源大模型的中型版本,而不需要做太多妥协。

与 Mac Studio 的较量
谈到竞品对比,田鸿飞显得相当自信。
"我们跟 Mac Studio Ultra M3 对比过,在运行C omfyUI(一款流行的 AI 图像生成工具)这个生图环节上,我们大概是 Mac Studio 的7倍速度。"
7 倍,这不是一个小数字。
Mac Studio Ultra M3 的售价是 5288 美元,而 Olares One 售价约3000美元。换句话说,Olares 在生图这个场景上,用 60% 的价格实现了 7 倍的性能。
这个性能差异的来源是 GPU 架构的根本不同。Mac Studio 使用的是苹果自研的M系列芯片,采用统一内存架构(UMA),CPU 和 GPU 共享同一块内存池。这种设计在通用计算和能效方面有优势,但在AI推理这种高度依赖 GPU 并行计算的场景下,NVIDIA的 CUDA 架构仍然是王者。
当然,这并不意味着 Mac Studio 是一款失败的产品。苹果的统一内存架构有一个巨大的优势:你可以在一台 Mac Studio 上运行参数量巨大的模型,因为内存容量可以做得很大(最高达192 GB)。但如果你的主要用途是生图、视频生成或其他高度依赖 GPU加速的 AI 任务,Olares 可能是更划算的选择。
开源的意义
"苹果是闭源,我们是开源。"田鸿飞反复强调这一点。
Olares 操作系统是开源的。这意味着:
- 极客用户可以把 Olares OS 安装在自己的服务器上,甚至是 AWS 的 VPS 上
- 开发者可以审查代码,确保没有后门或数据收集行为
- 社区可以贡献应用和优化
"有的比较极客的用户,可能会去 AWS 上搞一个 VPS 给装上去,其实也是 OK 的。"田鸿飞说。当然,这样做就牺牲了隐私优势——毕竟你的数据都在 AWS 上了。
开源还有一个更深远的意义:它是构建信任的基础。在一个 AI 模型可能记录你所有对话、分析你所有文件的时代,"开源"不仅是一种技术选择,更是一种价值主张:我们对你的数据没有任何想法,你可以自己验证。
Kickstarter 的惊喜
"我们最近刚刚完成 Kickstarter 的众筹,前天才结束。大概卖了不到 250 万美金。"
这个数字远超团队预期。他们原本的目标是卖出 400 多台,结果实际卖出了约 800台。"其实我们远超过我们自己的计划,我对我们还是挺出乎意料的。" 田鸿飞说。
这个众筹结果释放出一个重要信号:边缘 AI 硬件的市场需求是真实存在的,而且可能比大多数人想象的要大得多。在 CES 展会上,Olares 展位的访客聚焦于两个话题:隐私和数据主权。
"本来我以为这是个蛮小众的群体," 田鸿飞坦言,"但超乎我意料之外。"
03. 走进 Olares 的世界 —— 一次远程桌面体验
访谈中,Indigo 直接演示了 Olares 的使用体验。
首先,你需要给你的 Olares 分配一个域名。Indigo 的设备被命名为"REWIRED"——这是他家的名字。通过这个域名,你可以在任何地方、用任何设备的浏览器访问你的 Olares。
打开浏览器,输入域名,回车。一个看起来很像 Mac OS 的桌面出现在屏幕上。
"有点像 Mac OS 一样,但是它是 Web 打出来的,你可以远程访问。" Indigo 描述道。这个界面上有文件夹、应用图标、还有一个类似 Mac Dock 的任务栏。你可以挂载外部存储(比如已有的 NAS),可以安装各种应用,可以运行 AI 模型。
App Store:边缘 AI 的应用商店
Olares 有一个类似 App Store 的应用市场。打开"AI"分类,你会看到一系列已经针对Olares 优化适配的开源大模型:
- DeepSeek R1
- Gemma 27B
- GPT OSS(OpenAI 的开源模型)
- IndexTTS2(语音合成)
- 各种图像生成模型
"本地能跑的模型上面都能跑。" 田鸿飞说。
除了AI模型,应用市场还提供各种生产力工具:
- Excalidraw:一款流行的画板/草图工具
- Obsidian:知识管理和笔记软件
- WordPress:博客系统
- Mastodon:去中心化的类Twitter社交平台(国内叫"长毛象")
- Steam:没错,你可以在 Olares 上运行 Steam,玩《黑神话:悟空》
- Second Me:数字孪生项目
"我们最重要就是玩 Steam,我们玩黑悟空很流畅的。" 田鸿飞笑道。
这不是玩笑。因为 Olares 内置了高性能 GPU,它完全可以作为一台游戏服务器使用。你在家里放一台 Olares,然后在办公室、咖啡馆、甚至手机上通过 Steam Remote Play 来玩 3A 大作——所有渲染都在你家里的那台盒子上完成,你的设备只需要播放视频流和传输输入信号。
虚拟机与更多可能性
"这是可以装在虚拟机里面跑 Windows,对不对?"I ndigo 问。
"虚拟机是可以的。" 田鸿飞确认。
这意味着 Olares 的使用场景几乎是无限的。它可以是:
- 一台家庭AI计算中心
- 一台私人云存储服务器
- 一台游戏服务器
- 一台虚拟机宿主机
- 一台Web服务器
- 以上所有的组合
"就是一台PC,懂了。" Indigo 总结道。
但它又不仅仅是一台 PC。它是一台你可以远程访问的、为 AI 优化的、开源的、保护你隐私的 PC。这些定语的叠加,创造出了一个全新的产品品类。
04. 谁在使用边缘智能?三类核心用户画像
Kickstarter 众筹的结果给 Olares 团队提供了真实的用户数据。"我可以给你分享一下已经发生的事情,"田鸿飞说,"我们现在发现有三类用户。"
第一类:设计师
"第一类用户就是设计师。"设计师是AI图像生成技术的重度用户。无论是 Stable Diffusion、Midjourney 还是 ComfyUI,他们每天都要生成大量图像来做概念设计、素材制作、创意探索。
云端服务的问题在于:
- 排队:热门时段可能要等几分钟甚至几十分钟
- 流量:一个 1GB 的图片上传,然后几个 GB 的图片下载,速度受限于网络带宽
- 成本:按量付费的 Credits 很快就会烧完
"那就取决于你的工作量多大,对吧?你要买多少 Credit,你愿不愿意在那排队等,你这个一个 G 的图片上去,再等个几个 G 的图片下来,这个速度愿不愿意去等。" 田鸿飞分析道。
而有了本地设备,设计师的工作流程变成了:点击生成,几秒钟后出图,不满意就调参数再来,无限循环,不用担心任何外部限制。
这是一个"一次性买断 vs 按量付费"的经典商业模式对决。如果你是重度用户,买断几乎总是更划算的。
第二类:AI工程师
"还有一类用户就是硅谷大量存在这种 AI 工程师,他们每个人都要买一个高性能的机器,回家玩大模型的。"
这类用户的需求和设计师不同。他们不一定是为了"生产"什么,更多是为了"学习"和"实验"。
- 想跑一下最新的 DeepSeek 看看效果?本地跑。
- 想微调一个小模型?本地跑。
- 想测试一下 Agent 框架?本地跑。
- 想在不暴露代码的情况下做 AI 原型?本地跑。
对于 AI 工程师来说,一台高性能的本地设备是必备工具。它不是用来替代云端 GPU 集群的——那些训练大模型的任务确实需要数据中心级别的算力——但对于日常开发、调试、小规模实验来说,本地设备的响应速度和便利性是无可替代的。
第三类:小企业主
这是最出人意料的用户群体。
"可能我们一般没想到的,就是一般的小企业主。" 田鸿飞说。
他算了一笔账:
- 一个订阅服务 10 块钱/月
- 一个小企业主平均要订阅 20 个SaaS服务
- 一个月就是 200 块,甚至 400 块
- 一年下来就能买一台 Olares
更关键的是数据碎片化问题。如果你用 20 个SaaS产品,你的数据就分散在 20 个公司的服务器上。想做一个跨数据源的分析?想让AI帮你整合所有业务数据?几乎不可能。
"用我们的一个东西,一个产品,它可以装 20 个对应的开源软件在我们这个设备上,然后它所有企业的数据在一个地方。" 田鸿飞说。
这正是最近硅谷热议的话题:用 AI 来解决 SaaS 的问题。SaaS 的问题不仅是成本,更是数据孤岛。而边缘设备提供了一种可能性:把所有数据收归一处,然后用AI来统一处理。
05. 隐私、数据主权与商业模式的哲学
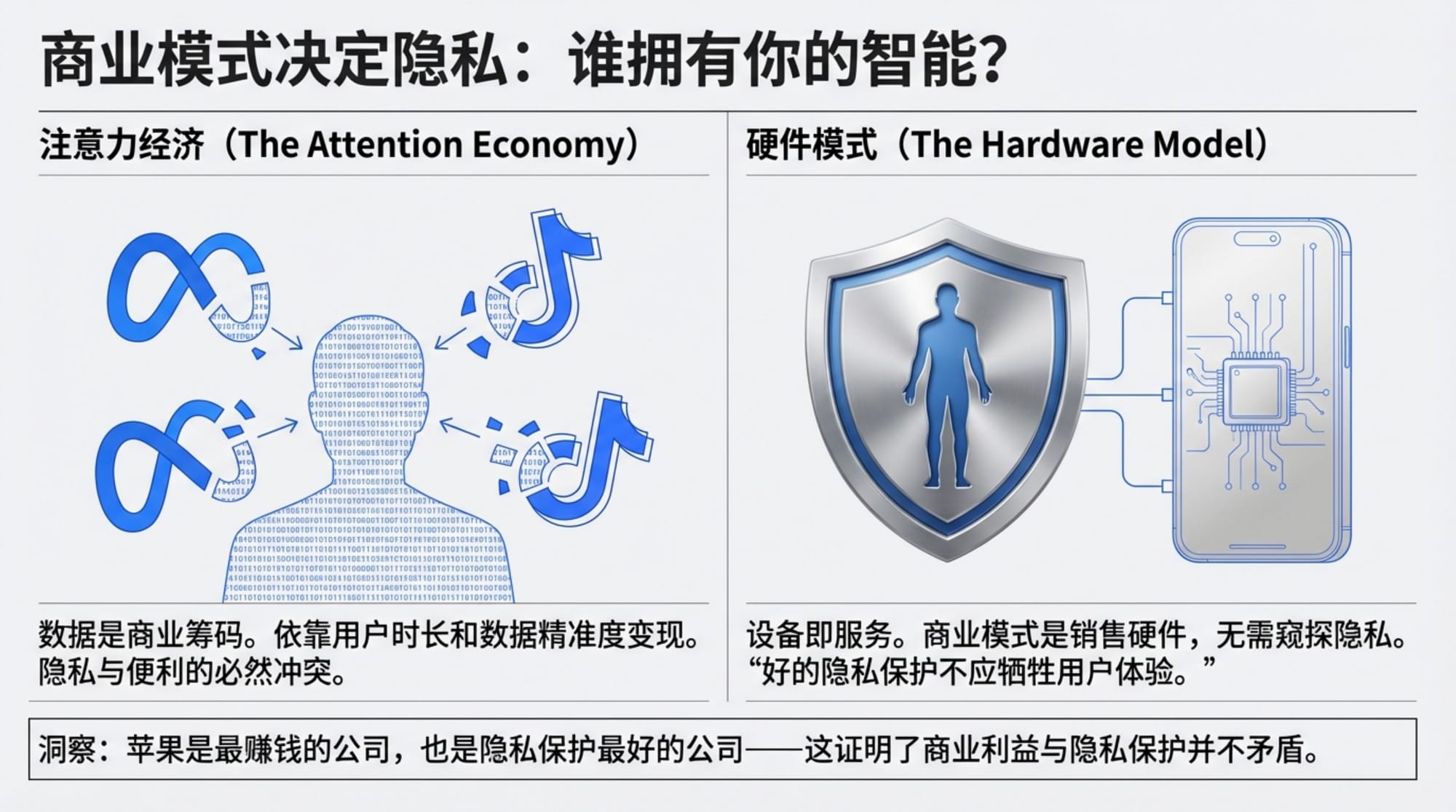
苹果模式的启示
在讨论隐私保护时,田鸿飞多次提到苹果。
"苹果的隐私是所有公司里边做得最好的,但是它又是一个最赚钱的公司。"
这句话点破了一个常见的误解:很多人认为,要保护用户隐私,就必须牺牲商业利益;或者反过来,要赚钱就必须出卖用户数据。
苹果证明了这是错误的二分法。
苹果的商业模式是卖硬件。你买了 iPhone、Mac、iPad,苹果就赚到钱了。它不需要你的数据来投放广告,不需要分析你的行为来推荐商品,不需要挖掘你的隐私来变现。
"所有人都选什么公司最安全,那一定是苹果最安全。因为它的商业模式就证明了它是保护你的隐私。因为它是卖设备给你赚钱的,你的设备越安全,你就越信赖它。"田鸿飞说。
这个逻辑链条非常清晰:商业模式决定了公司对待用户数据的态度。
社交网络的原罪
作为对比,田鸿飞提到了另一类公司:社交网络。
"你不像 Facebook,对,或者说中国叫字节或头条,或者说是腾讯,因为他都是在云端的东西来赚钱。特别是头条,你的所有的隐私的行为数据,都是它的商业筹码。"
社交网络的商业模式建立在两个支柱上:
- 用户时长:你刷得越多,它能展示的广告越多
- 数据精准度:它越了解你,广告越精准,广告主越愿意付钱
这意味着社交网络有内在的激励去做两件事:让你上瘾,以及收集你的一切数据。
"他不光是侵犯你的隐私,他还侵犯你的思维。" Indigo 补充道。这指的是算法推荐对人类认知的影响——信息茧房、情绪极化、注意力碎片化。
Google 的中间地带
在 隐私光谱上,Google 处于一个有趣的中间位置。
"这 Google 也是侵犯,因为你所有的数据,Google 都要拿去确定它的广告系统。" Indigo 说。
但相比社交网络,Google 有一个关键的区别:它不做那种"消耗时间"的社交信息流。Google搜索是一个工具——你用完就走。它会收集你的搜索记录来优化广告,但它不会用算法把你困在无限滚动的 feed 里。
"如果排行来看呢,肯定是苹果最安全,然后其次是 Google,然后才是 Meta。" 田鸿飞总结道。
边缘计算的价值主张
理解了这个商业模式的框架,你就能理解为什么边缘计算会成为一种价值主张。
Olares 卖的是硬件。它的商业模式和苹果一样:你买了设备,它就赚到钱了。它没有任何动机去收集你的数据,因为那对它的商业模式没有任何帮助。
更进一步,Olares 是开源的。这意味着即使你不信任团队,你也可以自己审查代码。它的隐私承诺不是一句口号,而是可以验证的技术事实。
"好的隐私保护并不会损害用户的使用体验,"田鸿飞说,"不是说你要为了隐私就要做很多事情,搞得很不好用。"
苹果已经证明了这一点,而 Olares 想在边缘 AI 的领域证明同样的事情。
06. 数字孪生 —— 比超级智能更重要的追求
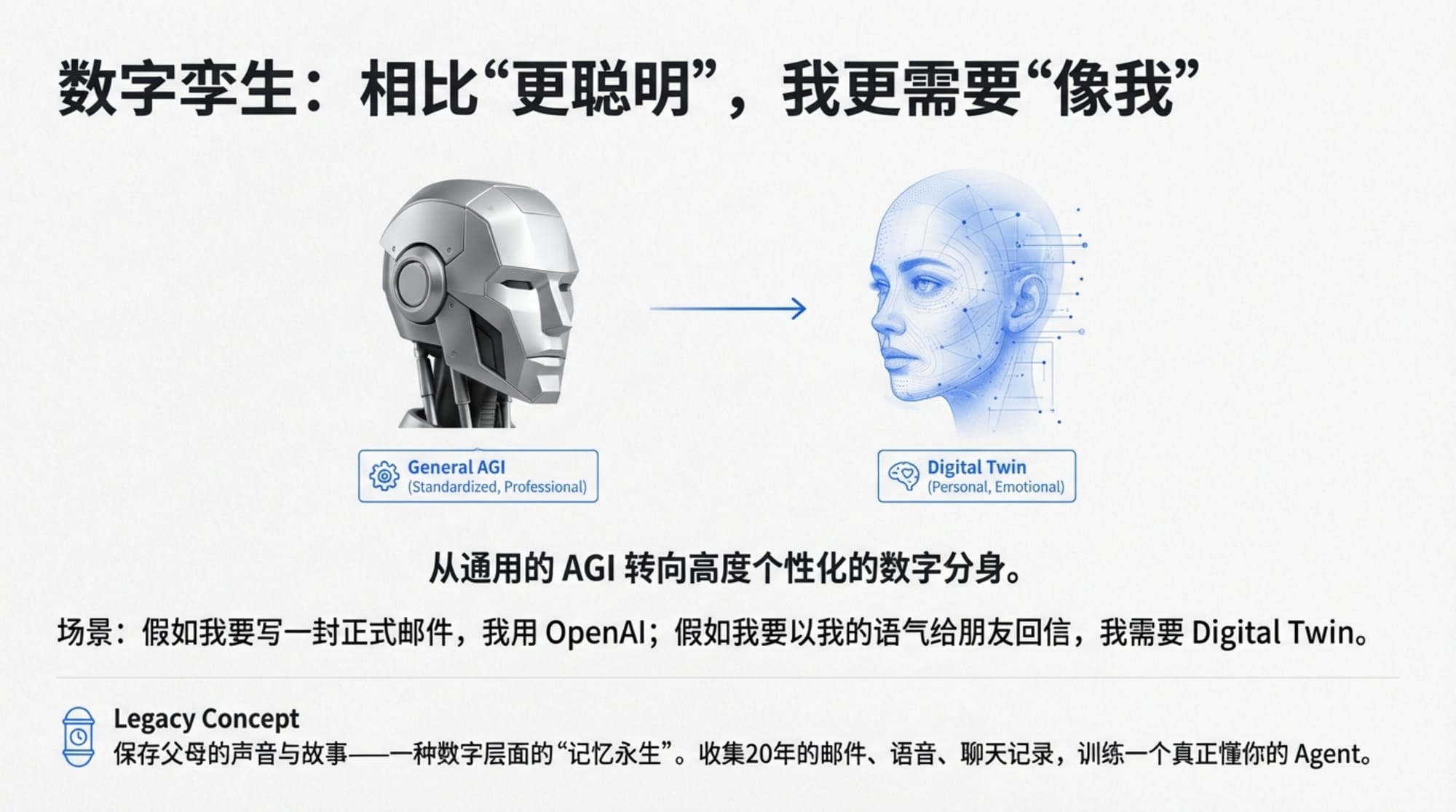
当所有人都在追逐 AGI 和超级智能时,田鸿飞提出了一个不同的问题:
"我其实不想做那么聪明的一个大模型,我只想做一个最接近于每个人的模型。"
他把这称为"数字孪生"(Digital Twin)。
"我不想这个模型比我聪明,但是它更像、最接近于我。我说话可能喜欢说'对啊对啊',它就应该说'对啊对啊'。"
这是一个被忽视的需求维度。当我们评价 AI 模型时,我们通常关注的是它有多"聪明"——能解多难的数学题,能写多复杂的代码,能通过多少 benchmark 测试。但"聪明"只是一个维度。
田鸿飞给了一个具体的例子:
"当我工作中去给客户写邮件的时候,我希望写一个非常正式的、非常漂亮的邮件,这时候我就用 OpenAI 来帮我写。但是我可能要跟你写邮件的时候,我希望这个大模型模拟我的语气,模拟一个朋友的话来给你写邮件,我就希望一个大模型更像我。"
不同的场景需要不同的"人格"。工作场合需要专业、正式、精确;朋友之间需要随意、亲切、带点个人风格。一个通用的超级智能可以做前者,但后者需要对"你"有深刻的理解。
数据的收集与整合
要创建一个"像我"的AI,第一步是收集数据。
田鸿飞提到他佩戴的 Limitless 设备——一个小小的胸针,可以 24 小时采集他的声音对话。
"然后如果我有一个这个,我再把 Gmail、再把所有我个人的数据都收集在一起,包括其实我 20 多年前的 Hotmail、还有读书时学校的邮箱邮件,我都其实都有保留。"
他想把这些数据——二十多年的邮件、数不清的对话录音、各种社交平台的发言——全部收集到一个地方,然后用AI来学习"他是什么样的人"。
"这个 Agent 可以来代替我在数字社会中做一些事情。" 田鸿飞说。
一个波士顿动力工程师的故事
这个想法引起了意想不到的共鸣。
"前两个星期从 CES 回家的时候,旁边坐了一个波士顿动力的工程师。然后我在说起这个想法的时候,他就说你这想法太好了。"
那个工程师分享了一个个人故事:他的老母亲现在整天对着 Siri 聊天。他想,如果有一个设备,能把她的聊天都记下来,那会是对她一生记忆的一个回忆。
田鸿飞有类似的感触:
"我的老父亲,其实他一生有很多故事。然后我小的时候他在忙,他没时间跟我讲;等他老了退休了想跟别人讲的时候,我其实在家里待的时间很少,他也没时间给我讲。那现在其实我想再有很多故事、想跟他问他以前故事的时候,现在已经不可能了。"
这触及了 AI 的一个深刻的人文意义:它可以帮我们保存那些本会随着时间流逝的记忆。一个人的声音、语调、用词习惯、思考方式——这些本来只存在于亲友的记忆中,会随着记忆的模糊和人的离世而永远消失。但如果有一个AI,在足够长的时间里听过这个人的话、读过这个人的文字,它或许可以成为一种"不完美的永生"。
《黑镜》的预言
Indigo 提到了英剧《黑镜》中的一集:
"有一集就讲这个了,你挂个东西把你去世的人的所有东西都收集下来,然后存在里面,有个公司然后把它给复原回来。"
这个剧情在几年前还像是纯粹的科幻,但今天,它的技术基础已经在慢慢成形。
语音合成可以复刻一个人的声音,大语言模型可以模仿一个人的说话风格,多模态AI可以生成一个人的影像。如果有足够多的数据,"数字复原一个人"不再是不可能的事情。
当然,这也带来了深刻的伦理问题:这样做是对逝者的尊重,还是对死亡的否认?"复原"出来的数字人是"他们",还是只是一个模仿品?我们应该用AI来缓解失去亲人的痛苦,还是应该学会接受失去?
这些问题没有标准答案,但技术已经在前进了。
07. 分布式智能 —— 超级智能的另一条路径
对话进行到这里,田鸿飞抛出了一个更宏大的话题。
"DeepMind 刚刚在 2025 年 12 月发布了一篇论文《Distributional AGI Safety》,就是说当所有人都集中在做超级智能、做单一超级智能体的时候,其实还有一种可能性:超级智能来自于多个没那么智能的智能体的协作涌现出来。"
这是一个根本性的视角转换。
当我们谈论 AGI 时,我们通常想象的是一个单一的、无所不能的系统——像《2001 太空漫游》里的 HAL 9000,或者《复仇者联盟》里的 Ultron。一个中央化的、全知全能的超级智能。
但如果超级智能不是这样产生的呢?如果它是从大量"没那么聪明"的小智能体的协作中涌现出来的呢?
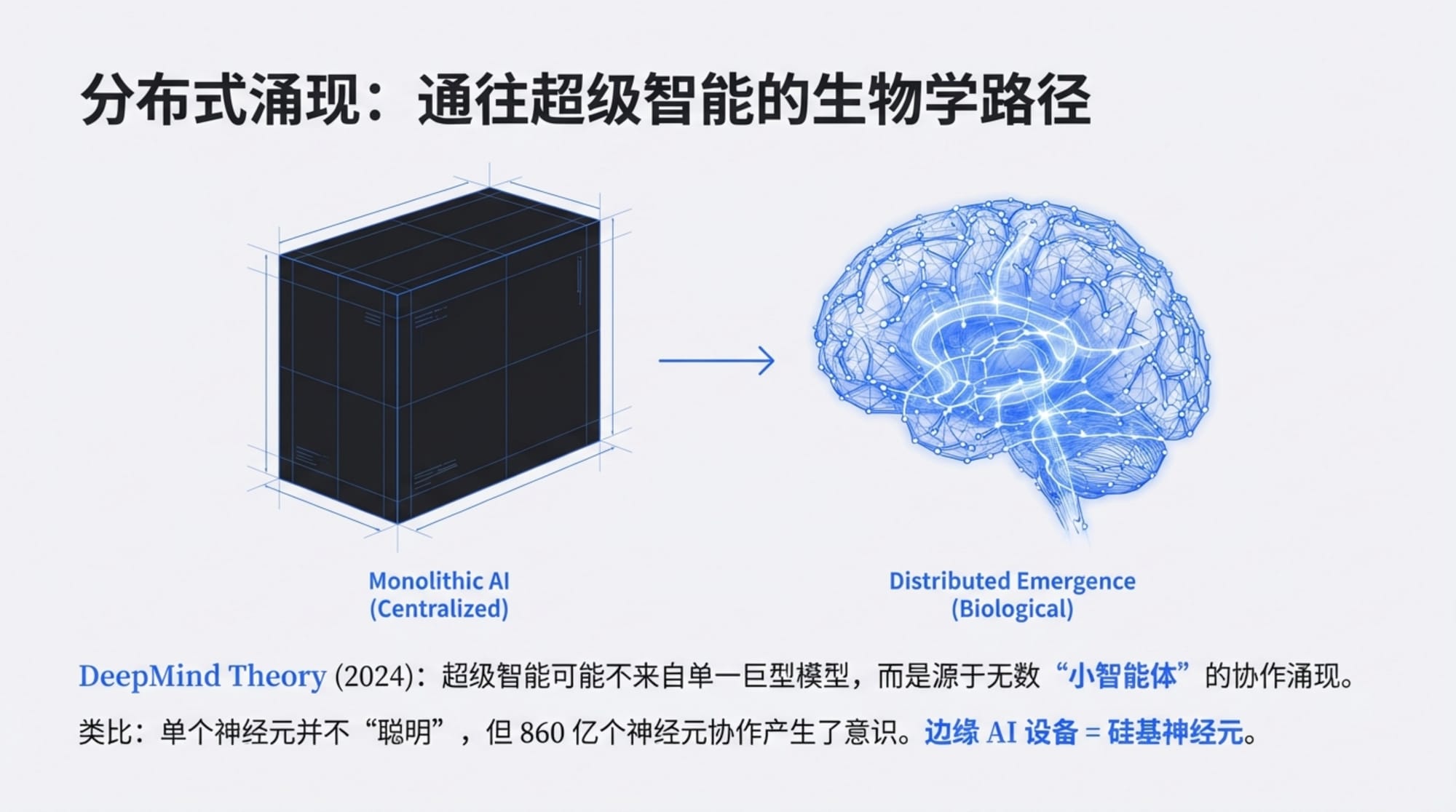
生物学的类比
这个思路有一个强大的生物学类比:大脑。
人类大脑由大约 860 亿个神经元组成。单个神经元是非常"笨"的——它只能做简单的加权求和和激活。但当 860 亿个神经元通过复杂的网络连接在一起时,意识、智能、创造力涌现了。
没有哪个神经元是"聪明"的,但整个系统是聪明的。
更宏观一点看,人类社会本身也是这个原理的体现。单个人类的智力是有限的,但当数十亿人类通过语言、文字、互联网连接在一起,通过市场经济进行协作时,人类作为一个整体展现出了惊人的集体智能——我们建造了城市、发明了互联网、登上了月球。
"人其实更多的时候,是人和人之间进行交互,然后共同通过市场经济来达到一个共同的目的。"田鸿飞说。
小模型协作 vs 单一大模型
田鸿飞提到了特斯拉的例子:
"特斯拉在做 100 万个 Human Simulator 来计算,他们一个观点其实很有意思:就是说相对于大家都在做大模型、参数越多越好的时候,他们在做一个小模型。他们的关键是——小模型可以 Iteration 更快,然后我也可以通过小模型之间的协作产生更多的智能。"
这是一个务实的工程选择。特斯拉的自动驾驶必须在车载芯片上实时运行,它不可能依赖云端——网络延迟会让你的车在做出反应之前就撞上障碍物。所以特斯拉被迫走小模型路线。
但这个"被迫"的选择反而可能指向一条不同的道路。
"这个是第一次听说到还有一个这么大的特斯拉在做这个方向,我觉得都是一个很有意义的探索。"主持人说。
数据的墙
讨论到这里,田鸿飞提到了一个业界共识:
"大家现在已经有共识了,就是说现在大模型训练的数据已经把世界上可能用到的数据已经都用完了,他们说叫碰到了数据的墙。然后98%的数据都是在私有的,是没办法被大模型采用的。"

公开互联网上的数据——维基百科、Reddit、GitHub、新闻网站——已经被各大AI公司爬了个遍。但这些只占全球数据的 2%。剩下的 98% 在哪里?
"这里面有相当大一部分数据是在企业的数据库里边," 田鸿飞说,引用了 Oracle 创始人 Larry Ellison 的观点," 他会都在 Oracle 数据库里边,然后是需要得到授权使用的。这是Oracle他们的一个战略,是如何帮企业更好运用数据来训练超级智能。"
还有一部分是个人数据:聊天记录、邮件、照片、语音备忘录、行程记录……这些数据极其分散,格式各异,散落在 Facebook、微信、Gmail、iCloud 的各个角落。
"如果我们大家就用 Olares 的话,我们可以用 Olares 作为一个个人数据的一个集中点。" 田鸿飞说。
这就回到了他们产品的核心价值主张:边缘设备可以成为个人数据的汇聚点,而这些数据可能是训练"真正像你"的AI的关键素材。
08. 群蜂智能 —— 一个已经存在的证明
股票市场:Agent 协作的先驱
田鸿飞抛出了一个惊人的论断:分布式智能体的协作网络已经存在了。
"其实我们最先一个由 Agent 自组织的这样一个交易网络,其实已经有了,已经存在了。我们的交易市场就是 Trading。"
Indigo 秒懂:"现在股票市场的 60% 交易量来自于高频交易,对吧?量化交易。"
这是一个被忽视的事实。当我们想象"AI 协作网络"时,我们可能想的是某种科幻式的未来场景。但实际上,全球金融市场已经是一个由算法主导的协作(或对抗)网络。
在纳斯达克、纽交所这些交易所,每天有数十亿次的交易发生,其中大多数是由算法自动执行的。这些算法——你可以叫它们"交易 Agent" —— 24 小时不间断地监控市场、分析数据、做出买卖决策。
它们之间没有"合作"的意图,每个 Agent 都只是试图为它的主人赚钱。但当成千上万个Agent 在同一个市场中交互时,一种复杂的集体行为涌现了:价格发现、流动性提供、风险定价……这些都不是任何单一 Agent "设计"出来的,而是从它们的集体交互中涌现出来的。
一个关于 Numerai 的故事
田鸿飞提到了一个有趣的公司:Numerai。
"最近有一个公司叫什么来着,他把所有的大模型跑去做交易。那公司本来我以为他是一个搞着玩的,后来我读了一下他们公司的博客,后来发现他们还是一个蛮严肃的做 AI 研究的公司。"
Numerai 的逻辑很有意思:他们认为金融市场的博弈是最难的AI任务之一,因为它是零样本学习的——市场永远在变化,历史数据的模式可能在下一秒就失效。所以他们把各种大模型放进这个"试验场",用真实的市场反馈来测试和改进 AI。
这是一个"让市场来检验 AI"的思路,而不是传统的"在学术 benchmark 上刷分"。
人类已经出局了
对话到这里,主持人做出了一个犀利的总结:
"所有人类都被淘汰出局,最后只剩机器跟机器在上面搏斗。"
田鸿飞认同这个观点:"其实这个已经在发生了。"
如果你是一个个人投资者,你可能还在用 K 线图、财报分析来做投资决策。但你面对的对手是什么?是能在毫秒级别做出反应的高频交易算法,是能同时分析成千上万条新闻的 NLP 模型,是有着 TB 级别历史数据和超级计算集群支撑的量化基金。
"我个人建议就是个人散户你就别进去在里面做高频交易跟 Agent 去搏斗了。"田鸿飞说,"对于人类来说,人类以后叫做投资,你做中长线就好了,做时间的朋友。"
这是一个务实的建议。在某些领域,人类已经不是 AI 的对手。但这不意味着人类完全出局 —— AI 在长期价值判断、战略思考、跨领域整合方面仍然不如人类。人类应该做的是找到自己的比较优势,而不是和 AI 在它擅长的领域硬碰硬。
"段永平前两天提到了这个事。" 田鸿飞提到了中国知名投资人的观点。价值投资的核心是理解企业的长期价值,而不是预测短期价格波动。前者仍然是人类的领地,后者已经是机器的战场。
09. Tesla & xAI 启示录 —— 一个关于 8 倍效率的商业逻辑
Elon Musk 的简单算数
特斯拉可能是世界上最大的边缘 AI 公司——它的每一辆车都是一个自主运行的 AI 系统,在本地处理感知、决策、控制。
Indigo 引用了一个 xAI 小工程师的采访(这里指的是 Sulaiman Ghori 的访谈):
"他说 Elon Musk 给他们的指令就是:人就是机器做得更好的事情,坚决不要人做。"
具体到数字,是这样的:只要比人快 8 倍,商业模式就成立。
"任何 Digital Work 的时候,比人快 4-8 倍,那这个商业模式就成立,就是我们一定会雇佣这个 Digital 的东西而不用人。" Indigo 解释道。
这是一个极其简单的商业逻辑。如果一个 AI Agent 能在同样时间内完成人类8倍的工作量,那么即使它的能力只有人类的 80%,它的性价比仍然是压倒性的。
"所以他脑子是很简单,就这样算算数就好了。" Indigo 说。
这意味着 AI 不需要比人类"更聪明"才能取代人类的工作 —— 它只需要"足够快"。
Microhard:xAI 的野望
Indigo 提到 xAI 的一个内部代号:Microhard。
"他说 Microhard,我要替代微软的,微软所有业务都可以用这个 AI 实现。"
这是一个惊人的野望。微软是全球最大的企业软件公司之一,它的 Office 套件(Word、Excel、PowerPoint)几乎是每一个白领的日常工具。如果特斯拉能用 AI 做出一个"更好的 Office" —— 或者更准确地说,一个让你根本不需要打开 Office 的 AI 助手——那将是对整个企业软件市场的颠覆。
"再比快 8 倍。" Indigo 补充道。
这就是 xAI 的逻辑:用足够快的 AI 来替代人类的数字工作,从而颠覆整个企业软件市场。这和 OpenAI、Anthropic 的路线完全不同 —— 后者在追求越来越"聪明"的模型,而特斯拉在追求越来越"高效"的执行。
SpaceX 的方法论
田鸿飞指出,这是特斯拉(或者说 Elon Musk)一贯的方法论:
"他用把 SpaceX 的这个模型再玩了一遍。用 off-the-shelf、最简单最便宜的材料来做大家都本来以为很难的事情。"
SpaceX 革命性的地方不在于它的火箭多先进,而在于它用了大量"现成的"、"便宜的"组件,然后通过软件和系统集成来实现性能。特斯拉的 AI 可能也是同样的思路:不追求最前沿的模型,而是用"够用"的模型做极致的工程优化。
"用特斯拉的 144 TOPS 的这个机器,这个人类模拟器,来解决 Office 的 Work。这个是蛮有意思的。" 田鸿飞说。
边缘算力的巨头格局
讨论到这里,一个更宏观的图景浮现了出来:世界上边缘算力最大的公司是谁?
田鸿飞给出了他的排名:
- 苹果:iPhone、iPad、Mac 加起来,苹果控制着全球最大规模的消费级计算终端。虽然单个 iPhone 的算力有限,但 iPhone 的数量是数以十亿计的。
- 特斯拉:在单一品牌下,特斯拉可能拥有仅次于苹果的边缘算力。北美有 400 万辆特斯拉,每一辆都配备了专用的AI芯片(目前主要是 Hardware 4,144 TOPS)。而且特斯拉可以通过 OTA 远程升级这些芯片的软件。
"所以我是这样看这两家公司的,他们两家公司都是边缘算力巨头。"田鸿飞说。
然后他加了一句:"还有我们。"
Indigo 笑了:"给你立了很大的榜样。"
这不完全是玩笑。Olares 的愿景正是成为边缘AI领域的一个重要玩家。当然,和苹果、特斯拉相比,Olares 目前的规模微不足道。但如果"边缘AI"真的成为下一个计算范式,那么今天的小玩家可能成为明天的巨头——就像 Google 在 2004 年只是一个搜索引擎,但后来成为了整个互联网的基础设施。
10. 从互联网到智能网络 —— AGI的另一种形态
光速的限制
对话的最后,主持人问了一个终极问题:
"你觉得在AGI、在超级智能到来的时代,边缘智能会是一个什么样的协同网络?"
田鸿飞的回答从一个物理学原理开始:
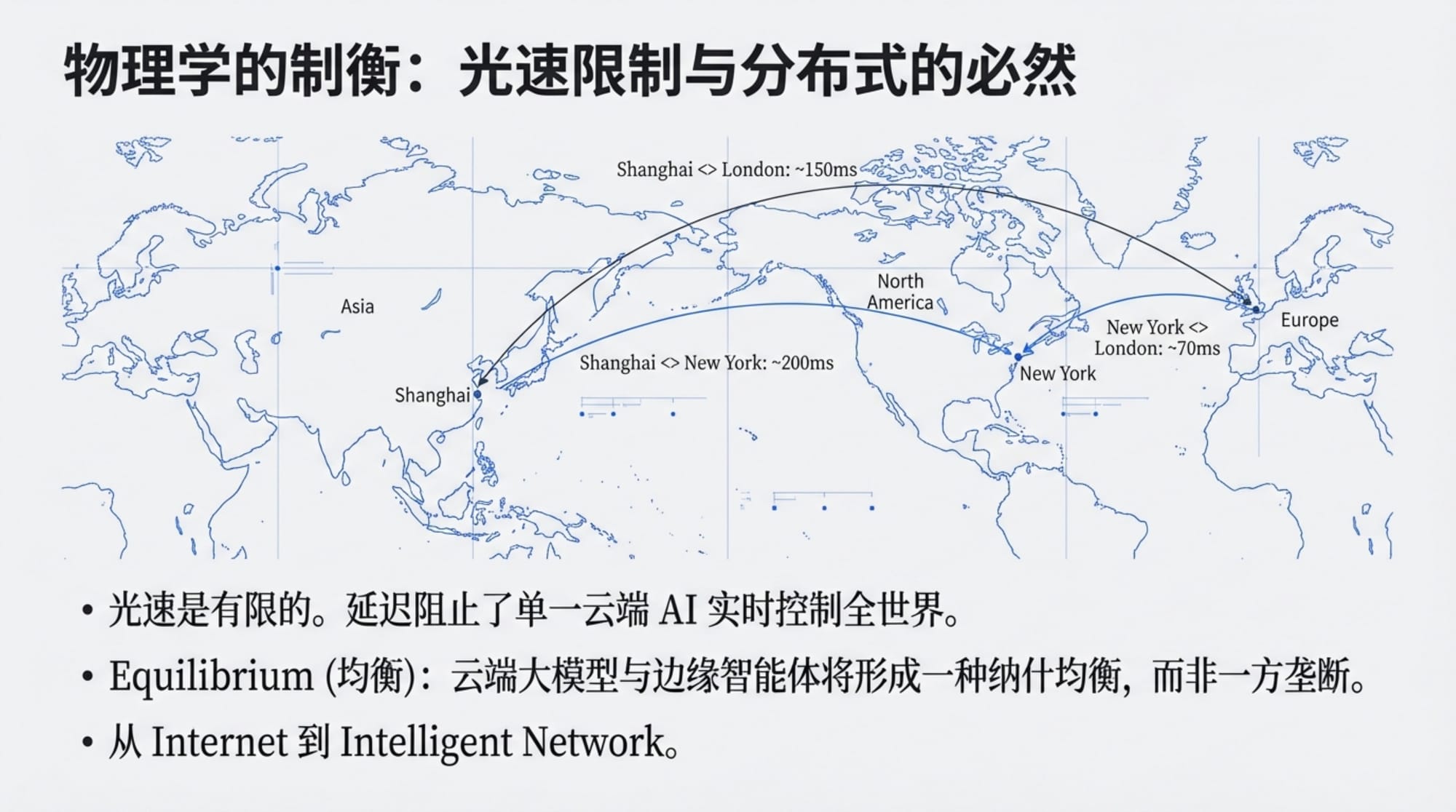
"Elon 说的一个很对:既然光速是有限制的,光速是有极限的,那么就不会出现一个垄断一切的超级智能。"
这是一个深刻的洞察。科幻小说里经常描绘一个无所不在、无所不能的超级智能,但物理学给这种想象设定了一个硬性上限:信息传递需要时间,而光速是信息传递的极限速度。
如果你在北京运行一个 AI,它想获取纽约的数据,光纤中的光至少需要几十毫秒才能跑完这段距离。如果它想控制月球上的机器人,信号往返需要 2.5 秒。如果它想影响火星上的任务,延迟是 4 到 24 分钟。
"因为你总是有上限嘛,那上限大家都会到上限,那上限我们怎么竞争呢?"田鸿飞说。
这意味着即使 AI 变得无限聪明,它也无法摆脱物理学的限制。在足够大的空间尺度上,中心化的控制是不可能的。分布式、去中心化的架构不仅是一种选择,而是一种必然。
均衡理论
"你能到达光速,我也能到达光速,那我们迟早要 PK 嘛。" Indigo 说。
这是博弈论的经典逻辑。如果每个参与者都能达到某种能力上限,那么最终的结局不会是某一方的绝对胜利,而是某种形式的均衡。
在 AI 的语境下,这意味着不会出现一个"统治一切的超级智能"。更可能的场景是多个智能体——有的在云端,有的在边缘,有的代表个人,有的代表企业——在某种协议框架下共存、竞争、协作。
"所以说不会存在这样一种超级智能,"田鸿飞说,"如果我们把智能推到极限,那我们就是每一个端侧的智能,或者服务器端的智能,你只要足够好、性能足够强大,那你就会——我们是均衡的力量。"
Intelligent Network 的愿景
对话的最后,两位老友勾勒出了他们共同的愿景:
云端将存在具有极高推理能力的大模型,因为数据中心的算力确实更大。但这些"超级智能"不会垄断一切。
边缘将部署大量的"次级智能",它们在本地处理日常任务、保护个人隐私、快速响应交互需求。
两者之间通过某种协议进行协作。边缘智能可以调用云端的大模型来处理复杂任务,云端模型可以利用边缘设备产生的数据来持续学习。
"以后我们互联网就不叫做互联网了,应该叫做 Intelligent,叫智能 Web。" Indigo 补充了一个更具体的场景:
"以后网站我开发一个服务,我都不是给人用的嘛。你看你现在 Computer Use,然后去看人类用的那些网站。如果说我想更高效,那我的 Agent 和你的 Agent,我们访问你的服务,我就一套 API,或者是一个什么 MCP,或者一套 Skill 协议就搞定了。这通讯效率巨高,所有东西都会可能是十倍百倍的提效。"
这描绘了一个 Agent-to-Agent 的世界:网站不再是为人类设计的图形界面,而是为 AI设计的 API 接口;交互不再是人类点击按钮,而是 Agent 之间的协议通信;效率的提升不是 10%、20%,而是 10 倍、100 倍。
区块链与 Agent 支付
当 Agent 开始代替人类进行交易时,支付系统也需要改变。
"Agent 支付肯定是用 Crypto 支付嘛。"Indigo 说,"直接绕过人类这一层了,都不需要人类的这个 KYC 的。"
这是区块链技术可能找到的一个真正的应用场景。人类的支付系统建立在身份认证(KYC)和法规合规的基础上,但 Agent 不是人——它没有护照,没有社会安全号,没有银行账户。如果 Agent 需要支付另一个 Agent 的服务费用,用传统的金融系统是极其笨拙的。
而加密货币天生适合这个场景:它是可编程的,不需要中间人,可以在毫秒级别完成清算。
"我们 Olares 的 ID,其实是基于区块链的 DID(去中心化身份)设计的。" 田鸿飞说,"我们虽然不是一个区块链企业,但是我们其实用了很多区块链的技术。我们有个信仰,是觉得未来的 Agent 和 Agent 之间的协作,如果是基于市场机制的协作的话,很可能会需要用到代币去支付对方的费用。"
这就闭合了一个逻辑环:边缘设备产生数据和执行任务,AI 模型提供智能,区块链提供身份和支付基础设施,所有这些组件通过开放的协议连接在一起,形成一个去中心化的智能网络。
结语:分布式的理想
这场长达七十多分钟的对话,从一款边缘 AI 设备开始,最终触及了关于智能、隐私、去中心化和人类未来的根本问题。
田鸿飞的技术轨迹 —— 从网格计算到比特币,从创新工场到 Olares —— 贯穿着一个一以贯之的理想:分布式、去中心化、个人主权。这不仅是一种技术偏好,更是一种价值主张:在一个日益中心化的世界里,个人应该有能力掌控自己的数据、自己的计算、自己的数字存在。
Olares One 只是这个理想的一个具体载体。它可能成功,也可能失败,但它代表的方向 —— 边缘 AI、个人云、分布式智能 —— 几乎肯定会继续发展。
当所有人都在仰望云端的超级智能时,也许我们应该低下头看看:真正的智能革命,可能正在我们每个人的桌上、口袋里、家里的角落中悄然发生。
正如田鸿飞在对话结束时说的:
"边缘算力以后是这个智能世界最大的一个趋势。云端他可能在做,但云端他也会把模型慢慢训练好然后边缘去部署。然后边缘会生成大量的硬件出来,最后来做计算。"
我们正站在一个分岔路口。一条路通向中心化的超级智能,由少数科技巨头控制;另一条路通向分布式的智能网络,由无数节点共同涌现。历史会证明哪条路是对的,但至少,选择权仍然在我们手中。
毕竟,光速是有限的,而人类的想象力不是。
本文基于 Indigo Talk 播客第 41 期整理创作,嘉宾:田鸿飞(Olares 联合创始人)